Skip to content
Skip to content Table of Contents
Why SLA-Driven Monitoring Runbooks for Managed IT Services Matter
Every managed IT services engagement has an SLA. Most of those SLAs describe response time commitments in clean, contractual language: P1 incidents resolved within four hours, P2 within eight, monitoring coverage guaranteed around the clock. The document is signed, filed, and referenced at the next quarterly business review.
What most SLAs do not have is the operational infrastructure to actually deliver what they promise. That infrastructure is the monitoring runbook, and its absence is the single most common reason SLAs are breached not through negligence or bad faith, but through the predictable failure of ad hoc incident response in an environment that demands structured, repeatable execution.
A monitoring runbook is a documented, step-by-step operational procedure that tells the engineer responding to an alert exactly what to do, in what sequence, with what escalation criteria, to resolve a specific class of incident within the time commitment the SLA defines. It is not a general troubleshooting guide. It is a precision instrument that converts an SLA commitment on paper into a repeatable operational outcome in production.
The data on what happens without this infrastructure is consistent across sources. Organizations using AI and automation in their incident response cut their breach lifecycle by 80 days and saved an average of $1.9 million per incident (IBM Cost of a Data Breach Report 2025). Industry benchmarks for top-performing managed security service providers set 2026 standards at mean time to detect under 15 minutes and mean time to respond under one hour (CompassMSP, 2026). The Softenger SOC Modernization Blueprint sets 2026 benchmarks at MTTD under 10 minutes and MTTR under one hour, with organizations deploying SOAR-integrated environments achieving MTTR 60 to 90 percent lower than those without structured automation (UnderDefense, April 2026). And organizations with MTTD below 200 days save an average of $1.1 million per incident compared to those with longer detection times (IBM Cost of a Data Breach Report 2025, via nflo.tech).
The enterprises and MSPs achieving those outcomes are not doing so through exceptional individual engineering talent. They are doing so through structured, documented, SLA-aligned runbooks that make the correct response procedure available to any qualified engineer at 3am on a Sunday, regardless of whether the senior engineer who originally solved this class of problem is available.
This guide defines what SLA-driven monitoring runbooks require, provides a working template for each major incident tier, and establishes the governance model that keeps runbooks aligned with both the SLA commitments they support and the environments they operate in.
Why SLA Commitments Without Runbooks Are Contractual Fiction
The gap between an SLA commitment and its operational delivery is almost always a process gap rather than a capability gap. The engineers exist. The tools exist. The commitment exists in writing. What does not exist is the documented procedure that connects those elements under time pressure, at any hour, for any engineer on the rotation.
Consider the operational reality of a P1 incident at 2am. A monitoring alert fires. An on-call engineer is paged. That engineer has between zero and four hours, depending on the SLA tier, to acknowledge, diagnose, contain, and resolve a critical infrastructure failure. Every minute spent deciding what to check first, which stakeholders to notify, whether to escalate, and how to communicate status to the client is a minute not spent resolving the incident.
Without a runbook, that engineer is doing three things simultaneously: technical diagnosis, process navigation, and communication management. All three under time pressure, with incomplete information, and with the SLA clock running. That is the operational condition that produces SLA breaches.
A well-structured runbook eliminates the process navigation and communication management components entirely. The engineer follows a documented procedure. Escalation criteria are predefined. Communication templates are pre-written. The diagnostic sequence is optimized based on the history of this incident class. The engineer’s cognitive capacity is focused entirely on the technical problem.
If a runbook is a static document, it is likely already obsolete (Uptime Labs, Enterprise Incident Response Plan, February 2026). That observation captures the other half of the runbook problem: the documents that do exist are frequently outdated, reflecting the environment as it was when the runbook was written rather than the environment as it currently operates. SLA-driven runbooks require a governance model that keeps them current, tested, and aligned with both the SLA commitments they support and the infrastructure they describe.
The Architecture of an SLA-Driven Monitoring Runbook

An SLA-driven monitoring runbook is structured differently from a generic incident response playbook. Every element of its structure exists to serve one objective: enabling consistent, rapid resolution within the time commitment the SLA defines.
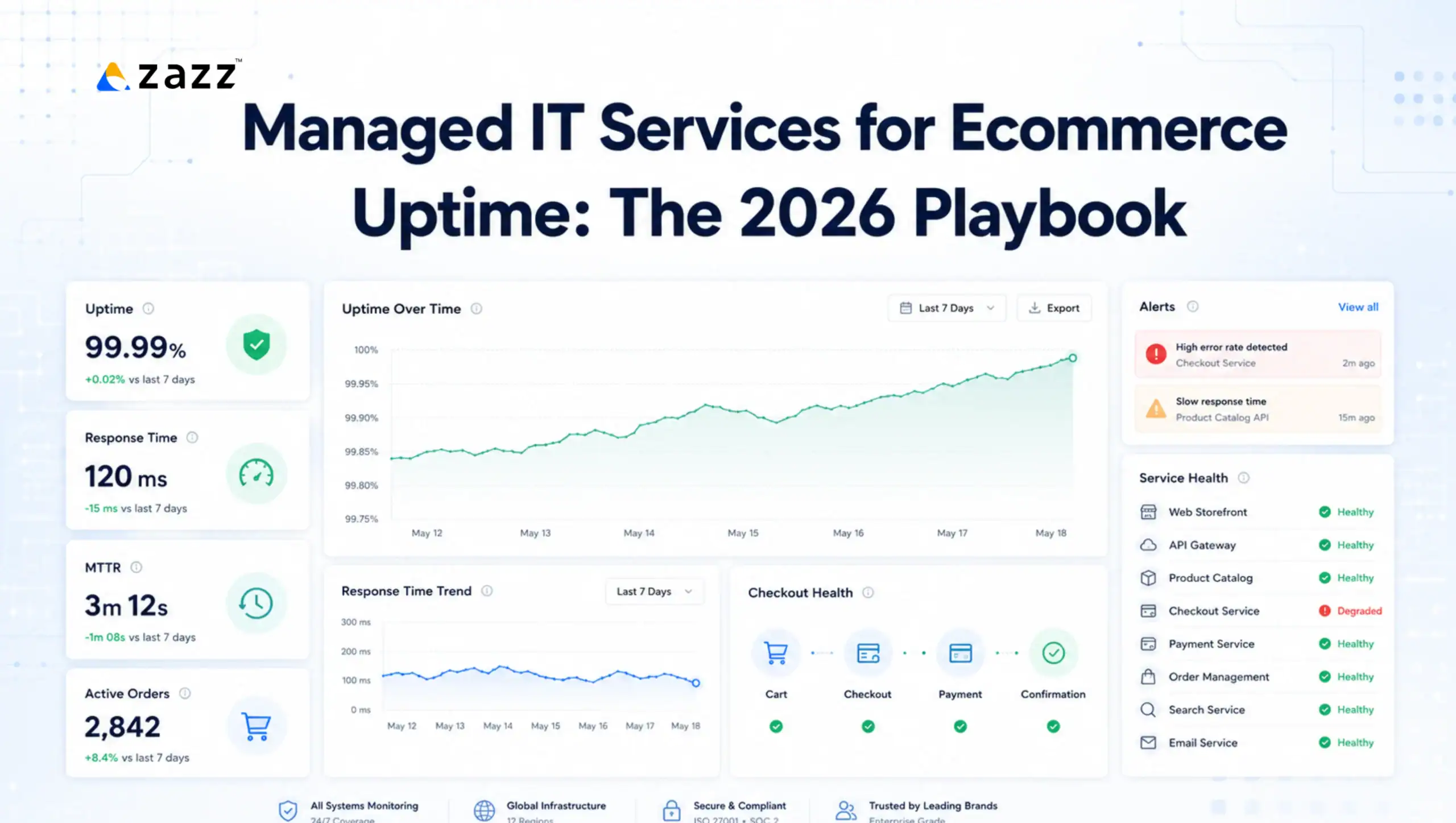
Seven core metrics encompass the entire incident lifecycle without inducing analysis paralysis: MTTR, MTTA, MTTD, MTF (mean time to fix), incident volume, first-time fix rate, and SLA compliance (TaskCall, January 2026). A well-structured runbook is engineered to drive each of these metrics toward target by eliminating the friction that inflates them.
The seven structural components of an SLA-driven monitoring runbook:
Component 1: Incident Classification and SLA Mapping
The first section of every runbook establishes which SLA tier this incident class falls under and what the specific time commitments are for acknowledgment, containment, and resolution. This is not a reference to the master SLA document. It is the specific time targets, expressed in minutes, that govern this runbook’s execution.
The SLA tier mapping should include:
- Priority level (P1 through P4) with specific criteria for classifying an incident at each level
- Time to acknowledge commitment in minutes
- Time to contain commitment in minutes
- Time to resolve commitment in minutes
- Business impact threshold that defines when escalation to the next tier is required
- After-hours applicability and whether SLA timers apply during maintenance windows
Organizations using structured KPI tracking are 2.5 times more likely to deliver projects on time and within budget (Netguru, citing research, September 2025). The same principle applies to incident response: when the time targets are explicit, tracked, and visible to every engineer on the incident, the organizational behavior aligns with the target rather than drifting toward whatever timeline the incident naturally takes.
Component 2: Alert Trigger and Detection Criteria
This section documents exactly what monitoring condition triggers this runbook: the specific alert, threshold, or combination of signals that indicates this class of incident is in progress. Specificity is essential. “Check the logs” is bad advice. “Check /var/log/syslog for error code 500” is good advice (Uptime Labs, Incident Response Runbook Best Practices, February 2026).
The trigger criteria should include:
- The specific monitoring alert or combination of alerts that activates this runbook
- The threshold values that distinguish this incident class from normal variation
- The secondary signals that confirm the primary alert represents a genuine incident rather than a false positive
- Known false positive patterns for this alert class and how to distinguish them from genuine incidents
The false positive qualification step is particularly important for SLA compliance because it determines whether the SLA clock has started. Alert fatigue, where engineers become desensitized to high-volume low-quality alerts, is one of the most significant operational factors in delayed incident acknowledgment. Runbooks that explicitly define how to confirm a genuine incident reduce the acknowledgment lag that inflates MTTA metrics.
Component 3: Immediate Containment Steps
This is the highest-value section of any SLA-driven runbook: the specific, sequenced steps that a responding engineer takes in the first minutes of an incident to stop the impact from expanding while diagnosis and resolution proceed.
Containment is distinct from resolution. Containment reduces the blast radius of an active incident. Resolution addresses the root cause. In an SLA-driven environment, containment must happen within minutes regardless of how long resolution takes, because uncontained incidents compound their damage with every minute they run.
Containment steps should:
- Be executable by any qualified engineer on the rotation without requiring specialist knowledge
- Be specific enough that there is no ambiguity about what action to take
- Include verification steps that confirm containment has been achieved before moving to diagnosis
- Never store credentials or API keys directly. Reference a named secrets manager and the specific credential path required (Uptime Labs, February 2026)
Component 4: Diagnostic Sequence
The diagnostic sequence documents the optimized investigation procedure for this incident class, based on the historical resolution patterns for incidents of this type. It represents the collective knowledge of every engineer who has previously resolved this class of incident, encoded in a form that makes that knowledge available to any engineer who encounters it.
An effective diagnostic sequence:
- Sequences investigation steps from most likely cause to least likely cause, based on historical incident data
- Includes specific commands, queries, and tool procedures rather than general descriptions of what to investigate
- Documents what each investigation step is expected to reveal, so the engineer can confirm whether the step produced the expected output or a deviation that indicates a different root cause
- Includes branch points where different diagnostic findings lead to different resolution paths
The observability dimension is increasingly important here. The shift from monitoring to observability, from “is it up?” to “how is it behaving?” across distributed traces and logs, requires runbooks that incorporate correlation procedures across multiple data sources rather than single-system investigation steps (Uptime Labs, Enterprise Incident Response Plan, February 2026).
Component 5: Escalation Criteria and Escalation Paths
Escalation criteria define the specific conditions under which the responding engineer transfers the incident to a higher tier, brings in a specialist, or notifies client leadership. These criteria must be objective and threshold-based rather than subjective and judgment-based, because judgment under pressure at 3am is unreliable in ways that explicit thresholds are not.
Escalation criteria should specify:
- The time threshold at which escalation is required if resolution has not been achieved (typically set to allow at least 25 percent of the SLA resolution window to remain after escalation)
- The technical conditions that trigger immediate escalation regardless of time elapsed: data loss confirmed, security breach suspected, regulatory notification obligation triggered
- Named escalation contacts for each tier, with primary and backup contacts and the specific notification method for each (page, call, message)
- The information that must be documented in the escalation handoff to prevent the receiving engineer from restarting the diagnostic process from zero
Explicit escalation criteria eliminate the hesitation that inflates escalation lag. When the engineer knows that the runbook requires escalation if containment is not achieved within 30 minutes, the decision is not a judgment call under pressure. It is a threshold that has already been reached.
Component 6: Communication Templates
Every SLA-driven runbook includes pre-written communication templates for each stakeholder audience at each stage of the incident lifecycle. These templates do not add communication quality at the cost of engineer time. They deliver adequate, consistent communication with zero engineer time, freeing the responding engineer to focus on resolution.
Templates required for each incident class:
- Initial notification to client stakeholders: confirms the incident has been detected, provides a brief description, states that the team is actively working on resolution, and commits to the next update interval
- Status updates at defined intervals: provides a brief current state, current containment and resolution status, and revised ETA if the initial estimate has changed
- Resolution notification: confirms the incident is resolved, describes what was resolved, states the duration of the incident, and commits to a post-incident review timeline
- Escalation notification: informs client leadership that the incident has been escalated, introduces the escalating engineer, and provides current status
Pre-written communication templates eliminate the most common source of client relationship damage in managed IT incidents: the gap between when the incident is detected and when the client is notified, driven by the engineer’s reluctance to communicate before they know more. Templates make the initial notification take thirty seconds rather than ten minutes, and clients consistently report that timely communication matters more than early resolution certainty.
Component 7: Post-Incident Actions and Runbook Update Trigger
The final section documents the post-resolution actions required to close the incident operationally: verification that the resolution is stable, restoration of any monitoring that was modified during the incident, documentation of the incident timeline in the ticketing system, and the post-incident review trigger.
Critically, this section includes the runbook update procedure. After every incident where a runbook was used, the responding engineer reviews whether the runbook accurately described the incident, whether any steps were incorrect or outdated, and whether the resolution introduced any information that should update the diagnostic sequence or escalation criteria. The runbook is updated immediately while the information is fresh (Uptime Labs, February 2026). This is the mechanism that prevents runbook obsolescence and converts each incident from a one-time cost into an operational improvement.
The SLA Tier Framework: What Each Priority Level Requires

SLA-driven runbooks must be explicitly mapped to the priority tier framework that governs the managed IT engagement. The following tier framework represents current industry standards for managed IT and managed security services, aligned with verified 2026 benchmarks.
SLA Tier Definitions and Performance Benchmarks:
Priority Tier | Definition | MTTA Target | MTTR Target | 2026 Industry Benchmark | Escalation Threshold |
P1 Critical | Complete service outage or security breach in progress affecting production | Under 5 minutes | Under 1 hour | MTTD under 15 minutes, MTTR under 1 hour (CompassMSP, 2026) | Immediate on detection |
P2 High | Significant degradation affecting multiple users or high-value systems | Under 15 minutes | Under 4 hours | MTTR under 5 hours (TaskCall, January 2026) | 30 minutes without containment |
P3 Medium | Single system or user impact, workaround available | Under 30 minutes | Under 8 hours | Next business day resolution acceptable for non-critical | 2 hours without resolution progress |
P4 Low | Minor issue, no immediate business impact | Under 2 hours | Under 24 hours | Standard queue resolution | End of business day |
Sources: CompassMSP 2026 MSSP Evaluation Guide, UnderDefense AI SOC SLA Guide April 2026, TaskCall Incident Management KPIs January 2026, Softenger SOC Modernization Blueprint via UnderDefense.
The MTTA target for P1 incidents deserves specific attention. AI SOCs achieve MTTA that approaches zero because AI begins investigating alerts the moment they fire, eliminating the human queue entirely (UnderDefense, April 2026). For MSPs operating manual or semi-automated monitoring environments, a five-minute MTTA target for P1 incidents requires a staffed operations center with on-call procedures that can page and receive acknowledgment in under five minutes. An on-call rotation where the engineer must be paged, wake up, log on, and navigate to the relevant system cannot reliably achieve that target.
The Monitoring Runbook Template
The following template provides the structural framework for an SLA-driven monitoring runbook. Each section heading is followed by guidance on what it should contain, designed to be adapted to specific incident classes and client environments.
RUNBOOK IDENTIFIER: [Unique ID for version control and reference]
INCIDENT CLASS: [Specific name of the incident type this runbook addresses]
SLA TIER: [P1 / P2 / P3 / P4]
LAST REVIEWED: [Date]
LAST TESTED: [Date]
REVIEW OWNER: [Named individual responsible for keeping this runbook current]
VERSION: [Version number]
SECTION 1: SLA COMMITMENTS FOR THIS INCIDENT CLASS
Time to Acknowledge: [Minutes]
Time to Contain: [Minutes]
Time to Resolve: [Minutes]
Business Hours Definition: [Hours and timezone]
After-Hours Applicability: [Whether SLA timers run outside business hours]
SLA Clock Start: [Specific trigger that starts the SLA timer: alert fire, client report, or first engineer acknowledgment]
SECTION 2: ALERT TRIGGER AND DETECTION CRITERIA
Primary Alert: [Exact alert name and monitoring system]
Trigger Threshold: [Specific value or condition]
Confirmation Step: [How to confirm this is a genuine incident, not a false positive]
Known False Positive Patterns: [Documented conditions that produce this alert without a genuine incident]
Secondary Signals: [Additional indicators that confirm incident severity tier]
SECTION 3: IMMEDIATE CONTAINMENT STEPS (Complete within [X] minutes)
Step 1: [Specific action. Include exact commands, queries, or tool procedures. Do not store credentials here. Reference: [Secrets Manager Path]]
Verification: [How to confirm Step 1 was successful]
Step 2: [Next specific action]
Verification: [How to confirm Step 2 was successful]
Step 3: [Continue until containment is confirmed]
Containment Confirmed When: [Specific observable condition that confirms containment is achieved]
SECTION 4: DIAGNOSTIC SEQUENCE
Most Likely Root Cause: [Most common cause of this incident class, based on historical data]
Investigation Step 1: [Specific investigation procedure, including exact location, query, or command]
Expected Output if Root Cause 1: [What the engineer should see if this is the root cause]
Resolution Path if Root Cause 1: [Link to or inline description of resolution procedure for this root cause]
Alternative Root Cause: [Second most common cause]
Investigation Step: [Specific investigation procedure]
Expected Output: [What the engineer should see]
Resolution Path: [Resolution procedure for this root cause]
[Continue for each significant root cause variant]
SECTION 5: ESCALATION CRITERIA AND CONTACTS
Escalate Immediately If:
- Containment not achieved within [X] minutes
- Data loss confirmed
- Security breach suspected or confirmed
- Regulatory notification obligation triggered
- Root cause cannot be identified after completing all diagnostic steps
Tier 2 Escalation Contact: [Named individual, contact method, backup contact]
Client Leadership Notification Contact: [Named individual, contact method, timing]
Escalation Handoff Minimum Documentation: [Incident start time, current status, steps completed, findings to date, current hypothesis]
SECTION 6: COMMUNICATION TEMPLATES
Initial Notification (send within [X] minutes of incident confirmation):
“We have detected [brief description of incident]. Our team is actively investigating and working toward resolution. We will provide the next update at [time or interval]. Current impact: [description]. Current status: Under investigation.”
Status Update (send every [X] minutes until resolution):
“Update on [incident description]: Current status is [containment achieved / in diagnosis / in resolution]. Estimated resolution time: [ETA or “We will update you in [X] minutes with a revised estimate”]. Steps completed: [brief description].”
Resolution Notification:
“[Incident description] has been resolved as of [time]. Duration: [total incident duration]. Resolution: [brief description of what was done]. A post-incident review will be scheduled within [X] business days. Please confirm service has been restored to your satisfaction.”
Escalation Notification (if applicable):
“We are escalating [incident description] to our senior [role] team. Current status: [brief description]. [Named engineer] is now leading the response. We will provide an update within [X] minutes.”
SECTION 7: POST-INCIDENT ACTIONS AND RUNBOOK UPDATE
Immediately After Resolution:
- Confirm monitoring has returned to baseline state
- Restore any monitoring rules modified during the incident
- Document incident timeline in ticketing system: detection time, acknowledgment time, containment time, resolution time, root cause, resolution steps
Runbook Update Review:
- Did any step in this runbook fail to produce the expected outcome? [Yes/No. If yes, document discrepancy]
- Was any information discovered during this incident that would improve the diagnostic sequence? [Yes/No. If yes, update Section 4]
- Were escalation criteria appropriate for this incident? [Yes/No. If no, document recommended change]
- Runbook update completed: [Date] by [Name]
Post-Incident Review:
- Schedule within [X] business days of resolution
- Attendees: [Roles required]
- Output: Documented root cause, preventive measures implemented, SLA performance assessment
The Governance Model That Keeps Runbooks Operationally Current
A runbook that is not maintained is a liability. It generates false confidence in a documented procedure that no longer accurately describes the response to the incident class it covers. The governance model for monitoring runbooks must address three specific failure modes: obsolescence through environment change, obsolescence through process drift, and obsolescence through team turnover.
Scheduled review cadence.
Every monitoring runbook should have a named owner and a defined review interval. Critical runbooks covering P1 and P2 incident classes should be reviewed quarterly. P3 and P4 runbooks require semi-annual review at minimum. Reviews should include a test execution: an engineer who was not involved in writing the runbook executes it against a simulated or test environment and documents any steps that are incorrect, outdated, or ambiguous.
Trigger-based update requirements.
In addition to scheduled reviews, specific events must trigger mandatory runbook review: any infrastructure change that affects the systems covered by the runbook, any SLA breach in an incident class where a runbook exists, any post-incident review that identifies a step discrepancy, and any personnel change that affects escalation contacts.
Version control and audit trail.
Runbooks should be maintained in version-controlled documentation rather than shared drives or email attachments. Every change should be logged with the author, date, and reason for the change. This version history serves two functions: it allows engineers to understand why a procedure is designed the way it is, and it provides the audit trail that demonstrates operational discipline to clients and compliance assessors.
Runbook coverage assessment.
Quarterly, the MSP should audit the coverage of its runbook library against its current incident history. Incident classes that appear in the history without a corresponding runbook represent operational gaps that will produce inconsistent response outcomes. The INOC incident management framework establishes that a knowledge base and runbook library covering virtually every technology scenario encountered is one of the primary differentiators of mature managed IT operations. Clients benefit instantly from accumulated knowledge rather than starting from scratch with documentation that typically takes years to reach comparable maturity (INOC, March 2026).
What Clients Should Demand From an MSP’s Runbook Program
Runbooks are one of the clearest indicators of an MSP’s operational maturity. An MSP that cannot share sample runbooks, escalation matrices, or evidence of a runbook review program is signaling operational immaturity regardless of what its SLA document promises (CompassMSP, 2026).
Clients evaluating or renewing MSP relationships should request the following as a standard part of due diligence:
- Sample runbooks for the three most common incident classes in their environment, with evidence of the last review and test date
- Evidence of the runbook governance program: who owns runbook review, what the review cadence is, and how post-incident updates are managed
- MTTD and MTTR performance data by incident tier for the prior 12 months, with SLA compliance rate by tier
- Evidence that escalation contacts in active runbooks are current named individuals rather than role titles
- The process by which a new client environment is incorporated into the runbook library and over what timeline full coverage is achieved
Providers who cannot share specific MTTD, MTTR, or uptime metrics may not be tracking them, which suggests operational immaturity and makes SLA enforcement difficult (CompassMSP, 2026). The same principle applies to runbooks: an MSP that cannot share sample runbooks is an MSP that either does not have them or does not have confidence in their quality. Neither position is compatible with the SLA commitments that govern the relationship.
The Connection Between Runbook Maturity and SLA Financial Penalties
SLA penalties are only meaningful when they are enforceable, and enforceability depends on measurement. Organizations employing SOAR-integrated AI SOC environments achieve MTTR 60 to 90 percent lower than those without automation (UnderDefense, April 2026). The financial difference that represents at an average downtime cost of $300,000 to $400,000 per hour for enterprise clients (Netguru, September 2025) is a direct argument for the investment in runbook infrastructure that makes that performance achievable and verifiable.
The standard penalty structure in managed IT SLAs involves tiered service credits: typically 5 percent credit per 0.1 percent uptime shortfall below the guaranteed threshold, and 10 percent credit if MTTR exceeds the target by more than 50 percent, with termination rights after three or more SLA breaches within a rolling 90-day period (UnderDefense AI SOC SLA Guide, April 2026). An SLA without financial penalties is just a marketing document (UnderDefense, April 2026). A penalty structure without the operational infrastructure to avoid triggering it is a financial liability.
The runbook program is the operational infrastructure that keeps the penalty structure from being triggered. It converts SLA commitments from aspirational statements into repeatable operational outcomes, and it converts post-incident reviews from blame exercises into improvement inputs. For both the MSP and the client, that is the value the runbook program delivers.
If your MSP engagement does not include a documented runbook program with verified SLA alignment and a defined review cadence, the gap between your contractual commitments and your operational delivery is already wider than it should be. Schedule a consultation with our team. We will assess your current runbook coverage, identify the incident classes with the highest SLA breach risk, and build the operational documentation infrastructure that makes your SLA commitments genuinely deliverable.