Skip to content
Skip to content Table of Contents
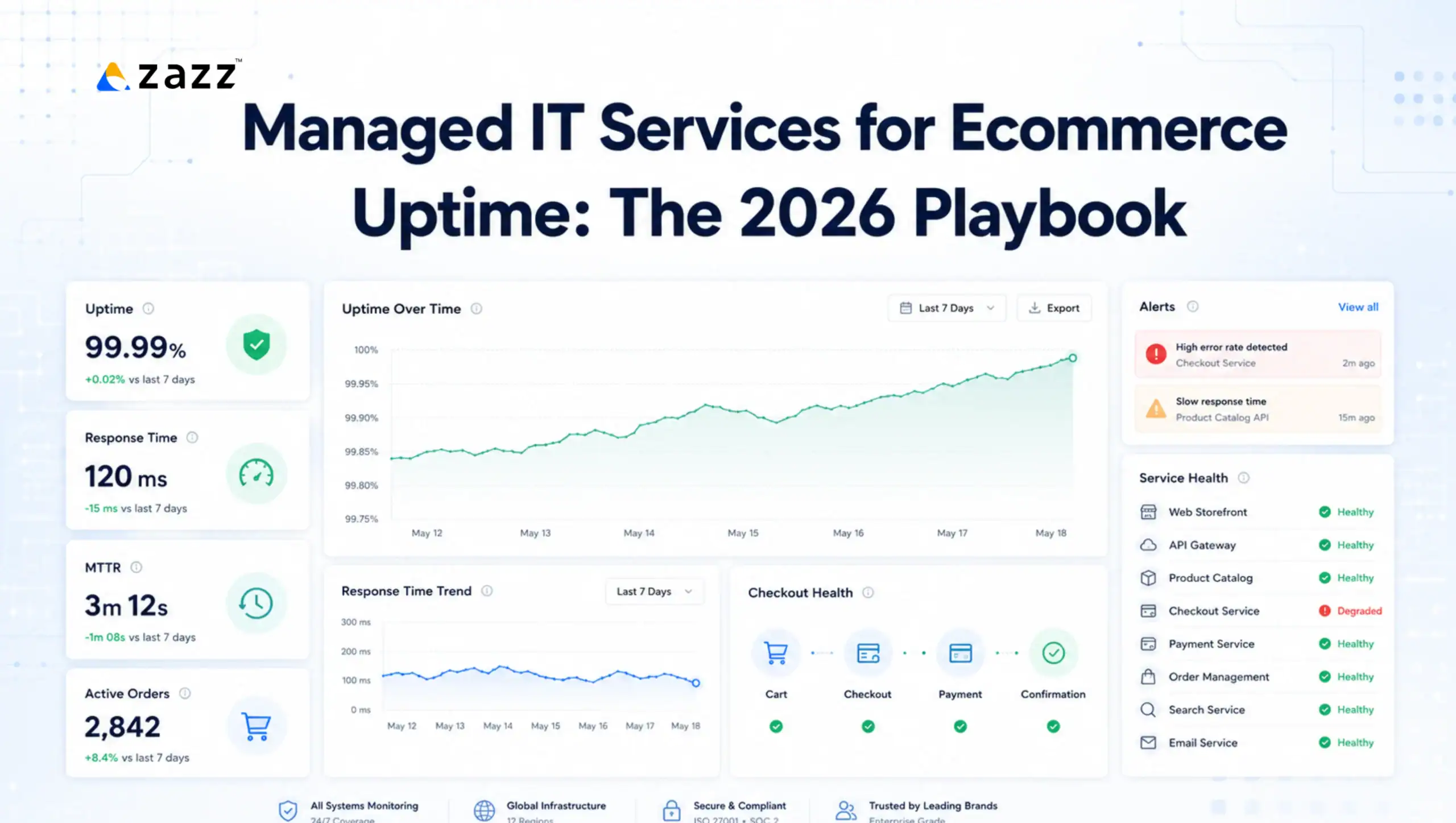
Cloud infrastructure does not fail randomly. It fails predictably, through the same categories of operational risk that appear in breach report after breach report, post-mortem after post-mortem, and budget overrun after budget overrun. Misconfigurations. Deployment failures caught too late. Alert queues that grow faster than teams can process them. Reliability commitments made without the engineering discipline to keep them.
Traditional IT operations was not designed to manage these risks at cloud scale. It was designed for a world of fixed infrastructure, predictable change windows, and relatively stable system boundaries. Cloud environments are none of those things. They are dynamic, distributed, continuously deployed, and architecturally complex in ways that conventional monitoring and incident response frameworks cannot adequately address.
Site reliability engineering, SRE, is the operational discipline that was designed specifically for this environment. Pioneered by Google and now adopted across the most operationally mature organizations in enterprise technology, SRE applies software engineering principles to infrastructure operations: replacing manual processes with automation, replacing reactive incident response with proactive reliability management, and replacing vague uptime aspirations with mathematically precise service level objectives and error budgets that make reliability measurable, accountable, and improvable.
SRE managed services bring that discipline to organizations that cannot build a full SRE function internally, and the performance differential against traditional IT operations is measurable across every dimension that matters to cloud operational risk.
The numbers establish why this matters. Over 90 percent of enterprises experienced at least one cloud security incident in the past 12 months, with vulnerabilities contributing to most breaches (DataStackHub Cloud Vulnerability Statistics, October 2025). Through 2025, 99 percent of cloud security failures were the customer’s fault, primarily due to misconfigurations (Gartner, via Fidelis Security, November 2025). The average enterprise operates over 3,000 misconfigured cloud assets across environments at any given time (DataStackHub, October 2025). 70 percent of misconfigurations remain undetected for weeks or months before exploitation (DataStackHub Cloud Breach Statistics, 2025 to 2026). And the average cost of a data breach caused by cloud misconfiguration is $4.45 million (IBM Cost of a Data Breach Report 2025, via Mayank Digital Labs, May 2026).
These are not security failures in the conventional sense. They are operational failures: the predictable consequence of managing cloud infrastructure with operational models that were not designed for it. SRE managed services are the operational model that is.
What SRE Managed Services Actually Are
SRE managed services are a specific model of outsourced cloud operations where the provider applies site reliability engineering principles, practices, and tooling to the management of a client’s cloud infrastructure and applications. They are distinct from conventional managed IT services in both their methodology and their commercial model.
The distinction that matters most is philosophical. Traditional IT operations treats operations as a support function: maintain what exists, respond when it breaks, escalate when the response exceeds capability. SRE treats operations as a software engineering problem: instrument everything, automate everything automatable, define reliability in measurable terms, and continuously engineer the system to improve against those measurements.
Leading organizations adopt a product and platform model that combines platform engineering for infrastructure with site reliability engineering, which uses software engineering practices and automation to manage application and infrastructure operations more effectively (McKinsey, June 2025). SRE managed services bring this model to organizations without the internal scale to build it independently.
The commercial model reflects this difference. Traditional managed IT services are typically priced on a device or user basis, with SLA commitments around ticket response time. SRE managed services are typically structured around reliability outcomes: SLO attainment, error budget consumption, change failure rate, and MTTR performance. The provider is accountable for the reliability of the system, not just the speed of the ticket queue.
How SRE Managed Services Reduce Cloud Operational Risk
Configuration Drift and the Misconfiguration Risk That Traditional IT Cannot Catch at Scale
Cloud misconfiguration is not an edge case. It is the default state of most enterprise cloud environments, and it is the single most significant source of cloud operational and security risk that organizations carry.
23 percent of all cloud security incidents in 2025 stem from misconfigurations (DataStackHub Cloud Misconfiguration Statistics, October 2025). 82 percent of misconfigurations are directly caused by human error, not provider flaws (DataStackHub, October 2025). 73 percent of cloud environments had at least one critical misconfiguration that could expose sensitive data, according to a 2025 study by Qualys (via Mayank Digital Labs, May 2026). Large enterprises experience an average of 3,000 or more configuration alerts per month (DataStackHub Cloud Misconfiguration Statistics, October 2025). And 65 percent of companies say they lack continuous validation for security settings (DataStackHub, October 2025).
Traditional IT operations addresses this risk through periodic manual review and point-in-time compliance assessments. The problem is that cloud environments change continuously: new resources are provisioned, existing resources are modified, infrastructure-as-code templates are updated, and every change is a potential configuration drift event. A manual review that happens quarterly is not detecting the misconfiguration that appeared three days after the last review.
SRE managed services address this through configuration-as-code and continuous automated validation. Infrastructure state is defined in version-controlled code rather than manual configuration. Every deployment runs through automated validation against security and compliance baselines before it reaches production. Drift from defined state triggers automated remediation rather than a manual review process. Automated scanning prevents roughly 40 percent of potential misconfigurations from escalating into breaches, while organizations using manual configuration management are twice as likely to experience repeated exposure incidents (DataStackHub Cloud Breach Statistics, 2025 to 2026).
The SRE approach additionally addresses Infrastructure-as-Code template misconfigurations, which contain security flaws in over 60 percent of reviewed deployments and lead to reproducible vulnerabilities because the same misconfigured template generates the same vulnerable resource every time it is deployed (DataStackHub Cloud Vulnerability Statistics, October 2025). IaC scanning is a standard component of the SRE managed services delivery model and a capability gap in most traditional IT operations programs.
Deployment Risk and Change Failure Rate
Every deployment to a cloud environment is a change event, and change events are the most common trigger for production incidents. The frequency of cloud deployments means that deployment risk management is not an occasional concern but a continuous operational discipline.
Progressive delivery strategies like canary releases detect 87 percent of service-impacting issues before full rollout, limiting the impact of failures (Harness.io, SRE 101 Guide, April 2026). Automated rollbacks reduce recovery time from an average of 57 minutes with manual processes to just 3.7 minutes, preventing widespread outages (Harness.io, April 2026). AI-driven verification shortens mean time to detection by 47 percent and resolution by up to 63 percent by automatically correlating metrics, logs, and traces under real traffic conditions (Harness.io, April 2026).
Traditional IT operations manages deployment risk through change control boards and scheduled maintenance windows. That model was designed for the cadence of on-premises infrastructure changes: infrequent, high-impact, carefully planned. Cloud-native applications deploy multiple times per day across multiple services. A change control process that adds days to each deployment does not reduce deployment risk in a cloud environment. It reduces deployment frequency, which reduces the organization’s ability to deliver product value and respond to operational issues through code changes.
SRE manages deployment risk through engineering practice rather than process gates. Canary deployments expose changes to a small percentage of traffic before full rollout. Feature flags decouple deployment from release, allowing code to be deployed to production while remaining inactive until explicitly enabled. Automated rollback systems detect degradation and revert to the previous known-good state without human intervention.
The DORA metrics, Deployment Frequency, Lead Time for Changes, Change Failure Rate, and MTTR, are the industry gold standard for quantifying delivery performance and reliability (Resolve.ai, via DataStackHub). SRE managed services are measured against these metrics. Traditional IT operations rarely tracks them.
The Deployment Risk Comparison: SRE vs. Traditional IT:
Deployment Risk Dimension | Traditional IT Operations | SRE Managed Services |
Deployment validation method | Manual testing and change approval board | Automated canary deployment detecting 87% of issues pre-rollout (Harness.io, 2026) |
Recovery from failed deployment | Manual rollback averaging 57 minutes (Harness.io, 2026) | Automated rollback averaging 3.7 minutes (Harness.io, 2026) |
Deployment frequency | Weekly to monthly in most environments | Multiple times daily with automated safety controls |
Change failure rate tracking | Rarely tracked as a formal metric | Core DORA metric with defined targets and trend monitoring |
Post-deployment validation | Manual verification or user-reported issues | Automated SLI monitoring detecting degradation in real time |

Observability Gaps and the Incidents Nobody Sees Coming
The median time from vulnerability disclosure to exploitation dropped to just 72 hours in cloud environments in 2025 (DataStackHub Cloud Vulnerability Statistics, October 2025). Attackers increasingly use automation and AI-driven scanning to detect vulnerable cloud assets in real time. The window between a vulnerability appearing and being exploited is narrowing consistently, and the organizations that detect incidents most quickly limit the damage most effectively.
Organizations with MTTD below 200 days save an average of $1.1 million per incident compared to those with longer detection times (IBM Cost of a Data Breach Report 2025). The average detection time for a configuration issue is over 180 days (DataStackHub Cloud Misconfiguration Statistics, October 2025). And 70 percent of misconfigurations remain undetected for weeks or months before exploitation (DataStackHub Cloud Breach Statistics, 2025 to 2026).
Traditional IT monitoring asks whether systems are up or down. Cloud-scale observability requires understanding how distributed systems are behaving across thousands of interdependent services, at a granularity and velocity that traditional monitoring tools and practices cannot provide.
SRE defines observability through the four golden signals: latency, which is response time; traffic, which is system demand; errors, which are failed requests; and saturation, which is system constraints (Netguru, Site Reliability Engineering Best Practices, January 2026). These signals provide a comprehensive view of system health and performance that goes significantly beyond the binary up or down status that traditional monitoring tracks.
SRE managed services implement this observability framework across the full stack: distributed tracing that follows requests across multiple services, log correlation that connects events across different system components, metric alerting calibrated to user-impact thresholds rather than generic resource utilization, and anomaly detection that identifies behavioral deviations before they become incidents.
The practical consequence is that SRE-managed environments catch incidents earlier, contain them faster, and learn from them more systematically than traditional IT-managed environments. AI-driven anomaly detection shortens MTTD by 47 percent compared to environments without it (Harness.io, April 2026).
SLO Breaches and the Reliability Commitments That Cannot Be Kept Without Engineering Discipline
Enterprise cloud applications carry implicit or explicit reliability commitments to customers, internal users, and regulated stakeholders. When those commitments are not met, the consequences range from customer churn to SLA penalty payments to regulatory action. Traditional IT manages reliability through infrastructure redundancy and incident response. SRE manages it through service level objectives and error budgets.
The SLO framework is the operational mechanism that makes reliability both measurable and manageable. A service level objective defines the acceptable performance threshold for a specific user-facing metric: 99.9 percent of requests complete within 200 milliseconds, or 99.95 percent availability measured over a rolling 30-day window. An error budget is the mathematical inverse of the SLO: if the SLO is 99.9 percent availability, the error budget is 0.1 percent, which translates to approximately 43 minutes of acceptable downtime per month (GetDX, SRE Complete Guide).
Error budgets are the SRE mechanism that balances reliability with innovation velocity. When the error budget is healthy, development teams have headroom to deploy new features and accept the reliability risk that comes with change. When the error budget is running low, deployment velocity slows and engineering attention shifts to reliability improvement. This creates a systematic, data-driven governance mechanism for the fundamental tension in cloud operations between moving fast and staying reliable.
Traditional IT operations has no equivalent mechanism. Reliability commitments are made in SLA documents, breaches generate post-mortems and apologies, and the cycle repeats. The SRE model converts that reactive cycle into a proactive engineering discipline where reliability degradation is visible before it becomes an SLA breach, and the operational decision to slow deployment velocity to protect reliability is made on the basis of error budget consumption data rather than crisis response.
Organizations implementing SRE practices have reported up to 35 percent improvement in uptime and a 44 percent decrease in operational expenses (Netguru, January 2026). Those outcomes are the direct commercial consequence of replacing reactive reliability management with proactive SLO-driven engineering.
Toil Accumulation and the Engineering Capacity That DisappearsIntoManual Operations
Toil is the SRE term for the manual, repetitive, automatable operational work that consumes engineering capacity without improving the reliability or capability of the systems being operated. Restarting services that crash on a predictable schedule. Manually scaling resources in response to predictable traffic patterns. Responding to alerts that always resolve themselves without human intervention. Processing routine access requests that follow a defined workflow.
SRE teams spend a significant portion of their time on engineering projects to reduce future toil, improving reliability through automation rather than manual processes (Netguru, January 2026). The standard SRE guideline, originating from Google’s SRE practices, is that no more than 50 percent of an SRE team’s time should be consumed by toil. The remaining 50 percent is dedicated to engineering projects that reduce future toil, improve reliability, or build better operational tooling (GetDX, SRE Complete Guide).
Traditional IT operations has no equivalent discipline. Manual work accumulates without formal measurement or accountability for reduction. Teams grow to absorb the manual work rather than engineering the manual work away. The operational cost of that model compounds with infrastructure scale: as the cloud environment grows, the toil grows proportionally, and the team required to absorb it grows with it.
SRE managed services break that scaling equation through automation investment. Routine operational tasks are automated as a primary engineering priority rather than an aspiration. The result is that the managed service scales more efficiently with infrastructure growth than a traditionally staffed operations model, and the engineering capacity recovered from toil reduction is reinvested in reliability improvements rather than headcount growth.
Incident Response at Cloud Scale and the MTTR Gap
When incidents occur in cloud environments, the complexity of distributed systems makes diagnosis significantly more challenging than in traditional infrastructure environments. A latency spike in a microservices architecture may involve any of dozens of interdependent services. A database performance degradation may be caused by a query introduced in a recent deployment, an infrastructure sizing constraint, a network issue, or a data volume threshold reached after months of gradual growth. Diagnosing the correct root cause quickly requires both deep observability tooling and the engineering expertise to interpret what it shows.
AI-driven verification shortens mean time to detection by 47 percent and resolution by up to 63 percent by automatically correlating metrics, logs, and traces under real traffic conditions (Harness.io, April 2026). The Softenger SOC Modernization Blueprint sets 2026 benchmarks at MTTD under 10 minutes and MTTR under one hour for critical incidents, with SOAR-integrated environments achieving MTTR 60 to 90 percent lower than those without structured automation (UnderDefense, April 2026).
Traditional IT incident response was designed for an environment where the scope of a failure is generally bounded: a server is down, a network segment is unavailable, a specific application has failed. Cloud incidents rarely present that clearly. They often manifest as degraded performance across multiple services, with the root cause requiring correlation across metrics, logs, and traces from multiple system components.
SRE incident response is engineered for this complexity. Runbooks are maintained for known incident classes. Observability tooling enables rapid correlation across system components. Automated detection identifies incidents through SLI degradation rather than user reports. Chaos engineering, which involves injecting controlled failures to validate self-healing mechanisms, validates that incident response procedures work under realistic conditions before a real incident tests them (Resolve.ai, DataStackHub). And blameless post-mortems convert each incident into a learning event that improves the system rather than a blame exercise that damages team culture.
The MTTR Performance Comparison:
Incident Response Dimension | Traditional IT Operations | SRE Managed Services |
Primary detection mechanism | Alert thresholds on individual systems | SLI degradation across user-impacting metrics |
Manual rollback MTTR | 57 minutes average (Harness.io, 2026) | 3.7 minutes with automated rollback (Harness.io, 2026) |
AI-driven MTTD improvement | Not typically implemented | 47% shorter MTTD (Harness.io, 2026) |
AI-driven MTTR improvement | Not typically implemented | Up to 63% shorter MTTR (Harness.io, 2026) |
Post-incident process | Root cause analysis and blame allocation | Blameless post-mortem with system improvement commitments |
Chaos engineering | Rarely practiced | Standard practice for validating self-healing mechanisms |
Where SRE Managed Services Beat Traditional IT: A Direct Comparison
The performance differential between SRE managed services and traditional IT operations is not theoretical. It is measurable across the specific dimensions that determine cloud operational risk.
Comprehensive Comparison: SRE Managed Services vs. Traditional IT Operations:
Dimension | Traditional IT Operations | SRE Managed Services | Verified Performance Differential |
Reliability management model | Reactive incident response | Proactive SLO and error budget governance | Up to 35% uptime improvement (Netguru, 2026) |
Operational cost structure | Headcount scales with infrastructure | Automation reduces scaling cost | 44% reduction in operational expenses (Netguru, 2026) |
Misconfiguration detection | Periodic manual review | Continuous automated validation | 40% of misconfigurations prevented by automated scanning (DataStackHub, 2026) |
Deployment risk management | Change control board approval | Canary deployment detecting 87% of issues pre-rollout (Harness.io, 2026) | 57-minute manual rollback vs. 3.7-minute automated rollback |
Incident detection speed | Alert thresholds on individual systems | AI-driven anomaly detection | 47% shorter MTTD (Harness.io, 2026) |
Incident resolution speed | Manual diagnosis and resolution | Automated correlation and rollback | Up to 63% shorter MTTR (Harness.io, 2026) |
Toil management | Accumulates without formal reduction target | Maximum 50% toil with active reduction engineering | Engineering capacity recovered from automation reinvested in reliability |
Observability model | Binary up/down monitoring | Four golden signals across full distributed stack | Behavioral anomalies caught before user impact |
Change failure rate | Rarely tracked | Core DORA metric with defined improvement targets | Systematic reduction through progressive delivery |
Cloud identity risk | IAM reviews on request | Continuous least-privilege validation | Cloud identities found 99% over-permissioned without active governance (DeepStrike, 2025 to 2026) |
When Does an Organization Need SRE Managed Services Rather Than Traditional IT?
Not every organization is at the stage where SRE managed services represent the right operational model. The transition point is determined by the characteristics of the cloud environment being operated rather than the size of the organization.
SRE managed services are the appropriate operational model when one or more of the following conditions apply:
Multi-service cloud architecture. When the cloud environment consists of multiple interdependent services, whether microservices, serverless functions, containerized workloads, or managed services from multiple providers, the operational complexity exceeds what traditional IT monitoring and incident response can address effectively. Microservices architectures create cascading failure scenarios that traditional operations cannot handle at scale (Harness.io, April 2026).
Continuous deployment cadence. When the development team deploys multiple times per day, change control board governance is incompatible with the deployment model. SRE’s progressive delivery approach manages deployment risk at continuous deployment velocity.
Measurable reliability commitments. When the organization has SLAs with enterprise customers, regulatory uptime requirements, or internal reliability standards that are formally tracked and carry commercial consequences for breach, the SLO and error budget framework provides the governance mechanism that makes those commitments manageable.
Cloud spend at material scale. When cloud infrastructure cost is a material budget line item, the FinOps dimension of SRE practice, which includes right-sizing resources, identifying idle capacity, and optimizing reserved instance coverage, delivers cost reduction that compounds with the reliability improvements.
Internal SRE capability gap. When the organization lacks the internal engineering talent to build and operate an SRE function, which is the most common condition given that 88% of organizations operate in hybrid or multi-cloud environments while the SRE talent market remains extremely competitive (SentinelOne, Cloud Security Statistics, February 2026), SRE managed services provide the capability without the hiring timeline and retention risk.
The SRE Metrics That Define Operational Success
The metrics that define SRE managed services success are different from the metrics that define traditional IT operational success, and that difference reflects the fundamental difference in the operational models.
Traditional IT metrics measure operational activity: ticket volume, ticket resolution time, system availability percentage, and patch compliance rate. SRE metrics measure operational outcomes: user-impacting reliability, deployment safety, engineering efficiency, and system learning rate.
The Core SRE Metrics Framework:
Metric | Definition | Why It Matters for Cloud Operational Risk |
SLO Attainment | Percentage of time service meets defined reliability target | Directly measures whether reliability commitments are being kept |
Error Budget Consumption Rate | Speed at which acceptable failure budget is being used | Fast burn rate signals reliability risk before SLA breach occurs |
Change Failure Rate | Percentage of deployments causing production incidents | Measures deployment risk and deployment engineering quality |
MTTR | Mean time to restore service after incident | Measures incident response effectiveness and automation maturity |
MTTD | Mean time to detect an incident after it occurs | Measures observability effectiveness and monitoring coverage |
Toil Percentage | Proportion of team time spent on manual repetitive work | Measures automation maturity and engineering capacity efficiency |
Deployment Frequency | How often code is successfully deployed to production | Measures delivery velocity and change risk tolerance |
Sources: DORA metrics framework, Google SRE principles, Netguru SRE Best Practices January 2026, Harness.io SRE 101 April 2026.

What to Demand From an SRE Managed Services Provider
The SRE managed services market is not uniformly mature. The gap between a provider that applies genuine SRE discipline and one that applies an SRE label to a traditional managed services offering is significant, and the questions that distinguish them are specific.
Questions that reveal genuine SRE capability:
- What SLOs will you define for our environment and how will error budget consumption be reported and acted upon?
- Show us your IaC scanning and configuration drift detection process and how quickly misconfigurations are remediated after detection
- What is your change failure rate for client deployments over the past 12 months and what progressive delivery mechanisms are you using?
- What percentage of your team’s time is allocated to toil reduction versus reactive operations and how is that tracked?
- Describe your chaos engineering practice: what failure scenarios do you inject, at what frequency, and what does a chaos engineering report look like?
- What are your MTTD and MTTR performance figures for cloud incidents over the past 12 months, broken down by incident tier?
- How are blameless post-mortems structured, who participates, and how are improvement commitments tracked to completion?
A provider that cannot answer these questions with specificity and current performance data is a provider applying an SRE label to a traditional operations model. The label is not the discipline.
The Compounding Advantage of SRE Discipline Over Time
SRE managed services compound in value over time in ways that traditional IT operations do not. Each blameless post-mortem produces system improvements that reduce the frequency of that incident class. Each toil reduction project recovers engineering capacity that is reinvested in further reliability improvements. Each chaos engineering exercise validates and improves self-healing mechanisms. The error budget governance model continuously calibrates the balance between deployment velocity and reliability based on actual performance data.
The result is an operational model that gets measurably better over time rather than maintaining a steady state. Organizations implementing SRE practices report up to 35 percent improvement in uptime and 44 percent reduction in operational expenses (Netguru, January 2026). Those outcomes are not achieved at go-live. They are the compounding result of continuous SRE engineering investment over months and years.
Traditional IT operations does not compound in this way. Incident response improves marginally as engineers gain experience, but the underlying system complexity grows faster than manual operational discipline can address it. Cloud environments scale. Dependencies multiply. The operational burden grows with infrastructure scale rather than being systematically reduced through automation investment.
The question for CTOs and engineering leaders evaluating their cloud operational model is not whether SRE principles produce better outcomes than traditional IT operations. The evidence on that is settled. The question is whether the organization’s current cloud environment has reached the complexity threshold where the investment in SRE managed services is justified by the operational risk it reduces and the reliability improvement it compounds.
For most organizations operating multi-service cloud environments with continuous deployment cadences and measurable reliability commitments, that threshold has already been crossed.
If your cloud environment is operating on a traditional IT operations model and you want to understand the gap between your current operational risk profile and what SRE managed services would close, schedule a consultation with our team. We will assess your current environment against the SRE capability framework, quantify the operational risk your current model is carrying, and map the transition path to SRE-managed operations that delivers measurable reliability improvement from the first quarter.